XiXiChat-14b-Beta
XiXiChat-14b-Beta has a 14 billion parameter base model and a short Q&A chat model tailored for agricultural scenarios. The current beta version is trained by around specific 50,000 Q&A data. Some examples are listed below.






Close-Beta Guideline
Although our model has made some breakthroughs in the specific-domain, it still has some problems (e.g., the fine-grained specific and geographical planting problems are still partially incorrect), so we plan to organize a close-beta, and we sincerely invite all you to provide valuable opinions on our model. Due to the limited energy of our group, the test is only for on-campus users in Northwest A&F University at the moment (close-beta). Please access 172.29.1.136:8080 via the campus LAN.
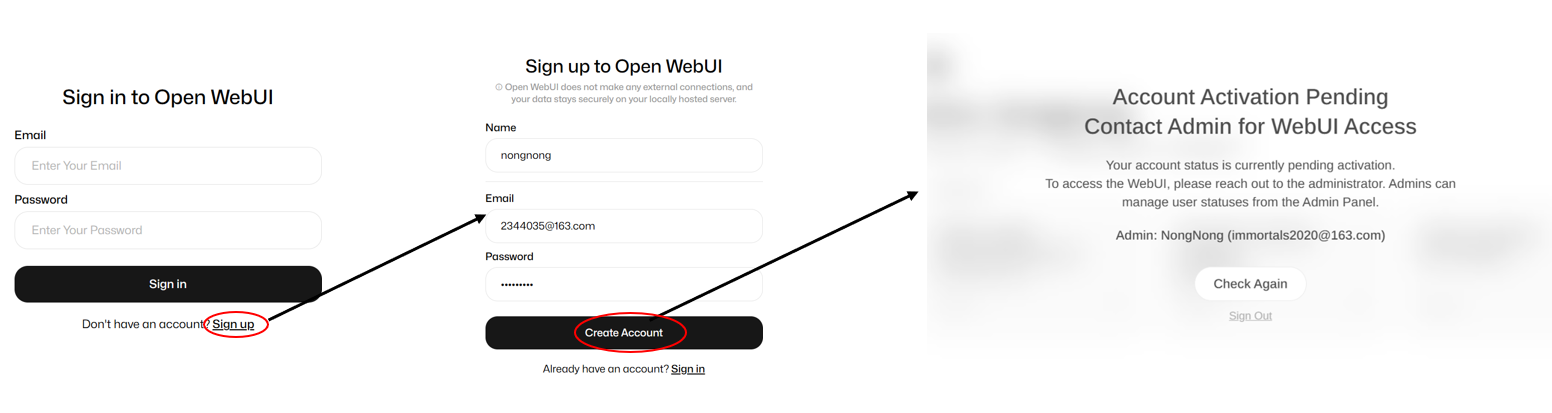
Sign up
For the first use, please register by submitting the required information. Once you've completed your registration, send your account details to immortals2020@163.com along with a description of your identity for review. An administrator will assess your submission, and upon approval, your user account will be successfully activated.
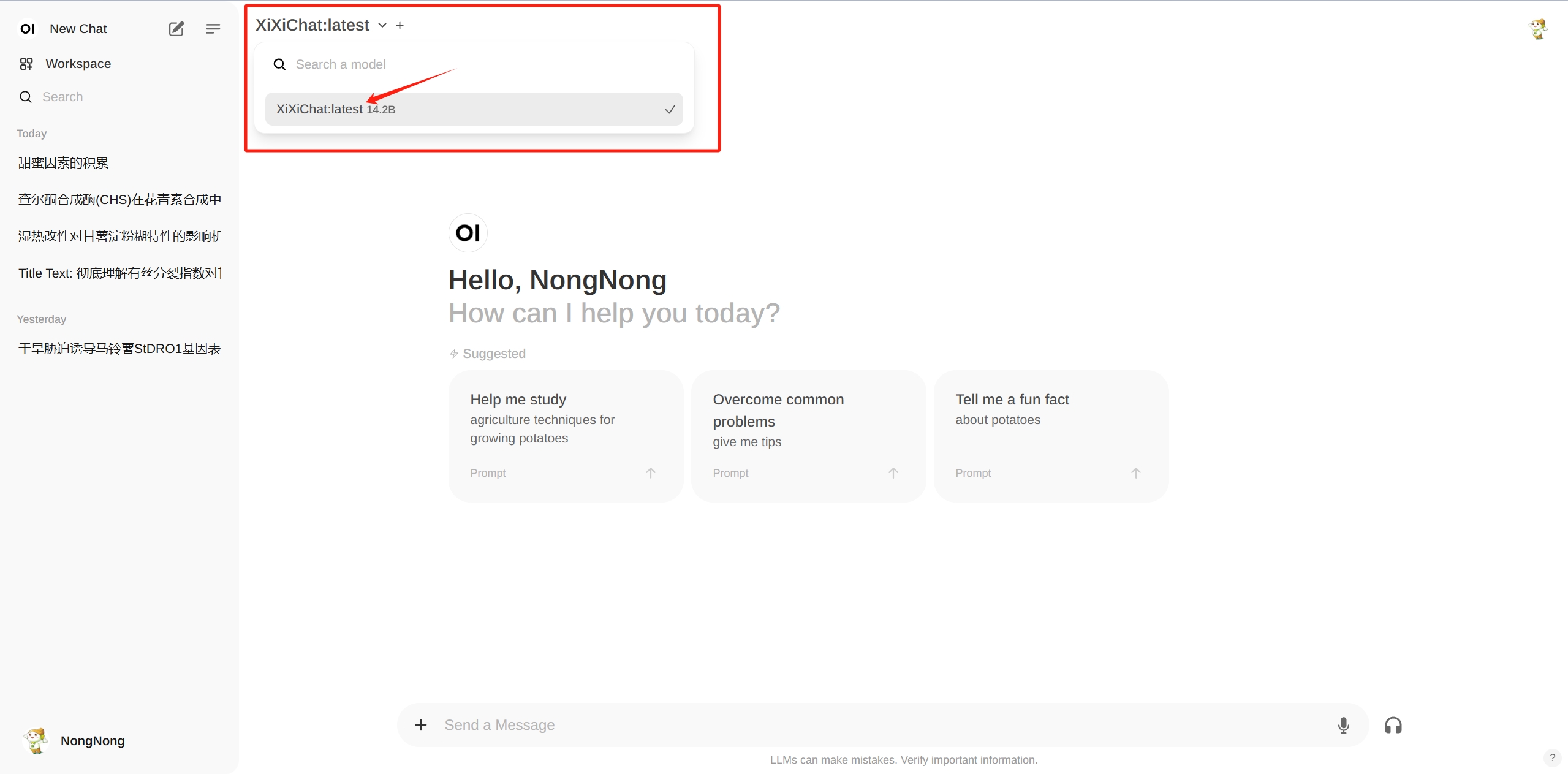
Select a model
Click the top left corner, select the XiXiChat:latest 14.2B model, and once successfully selected, you can begin the question and answer session.
Limitions
Due to limited device computing power, we currently support a quota of 50 model uses per person per day, which we will continue to increase in the future.